Exploit Equivalence Classes

A long time ago I went to a small university in New Zealand to get a math degree. It was one of those things that happened mostly through inertia -- like most kids I knew, I wasn't super interested in studying. I signed up for a bunch of classes, but only got through a year before I dropped out to move to Australia to work for a security startup. Hacking was more exciting, and there were a lot of good hackers in Australia.
When I came back to New Zealand after that adventure, I eventually dragged myself back to school. I thought that maybe I could be a cryptographer one day, because how hard could it be to find a preimage attack in SHA1? It turns out that it's pretty hard though, and hacking was (and is) much easier than cryptography. Still, I did manage to finish that math degree eventually.
You can't help but pick up a few concepts along the way, and you can't help but apply those concepts in later life. It changes how you think. Unfortunately whenever you map math to something that isn't math, the concepts are so warped and imperfect that you typically just end up trying to sound smart with math words. It's a hard habit to break though.
Anyway, here's a common problem in security research and vulnerability management: how do we know if a bug is exploitable or not?
The basic answer is obvious: write an exploit for the bug. The problem is that not everybody who wants to understand the exploitability of a bug actually knows how to write exploits (and nor should they). And even if you can write exploits, it's expensive and takes a lot of time. Even worse, the failure to write an exploit doesn't prove anything about non-exploitability, because perhaps someone else can write the exploit even if you can't. So "just write an exploit" is not a viable answer to the problem in a lot of cases.
For a while now I've been using a mental model based on equivalence classes to help answer this question without having to write a new exploit for every vulnerability.
Equivalence classes are a simple concept in set theory, it's just a group of objects that are considered equal in some way. Take even and odd numbers for example: you can say that all the odd numbers are in one equivalence class, and all the even numbers are in another. With only a little bit of effort, we can apply this concept to the "bug exploitability" problem.
The first step is to stop thinking about bugs, and start thinking about primitives. A bug is just a mismatch between what a programmer intended and what a programmer actually implemented, like "buffer overflow", "use-after-free", or "path traversal". A primitive is a generic behavior that you can achieve with that bug, like "arbitrary memory write with an arbitrary value", or "open and write to any file in any directory".
Usually you can take a primitive and boost it into a new and better primitive, like turning a small linear overwrite into arbitrary read/write. And usually you can take two or more different bugs and combine their primitives to create new primitives, like combining a memory corruption bug and an information leak to get arbitrary code execution.
An exploit is just a collection of primitives that are cleverly stitched together to do something that we all agree is unexpected. Of course it's obvious that a bug is exploitable when someone has written an exploit for it -- but most bugs are never exploited, and we still want to know if it could be exploited. This is exactly why Microsoft security advisories have the exploitability index, with labels like "exploitation unlikely" or "exploitation more likely": it's useful to assess risk in terms of exploitability.
That brings us to exploit equivalence classes. Let's say you want to go beyond a confidence assessment and actually prove that a new bug is exploitable. We know that the first approach is to write an exploit, but there is a second option as well: use an already existing exploit for a previous bug to make logical conclusions about exploitability that also apply to your new bug.
The idea is to build an equivalence relationship between bugs. Whenever we successfully write an exploit, we are establishing an equivalence class for all of the similar bugs that give the same primitive(s). Then when we find a new bug, if we can point back to a previous exploit and assert that we belong to the same exploit equivalence class, then we can claim exploitability without having to write a new exploit.
Of course this is an over-simplification, and the word "similar" is doing a lot of heavy lifting here. Similar means very similar, i.e. the same primitives, the same platform, the same set of exploit mitigations, the same set of security settings, and so on. If the primitive that the bug allows is even slightly different, or if the environment changes in some way, then there's no guarantee that an exploit equivalence class exists.
This means that if a new exploit mitigation is shipped in an operating system, it can potentially invalidate the exploit equivalence class for all previous exploits. At that point it's up to security researchers to show that an equivalence class still applies, or that a new equivalence class can be created. Perhaps you can show that the exploit mitigation isn't relevant or can be trivially bypassed, or perhaps you can demonstrate a new exploit technique.
I suspect exploit developers and security engineers are already intuitively using this concept to assess exploitability, but the actual process they use isn't documented and to my knowledge there isn't any shared terminology or even really a common understanding of what we're doing.
Here's a quick example. In JavaScript exploits, we commonly see two powerful primitives: "addrof" and "fakeobj". The technical details are all covered in this Phrack post by Saelo. Once you have shown that your bug gives you these primitives, you know that it's exploitable. The equivalence class is well established.
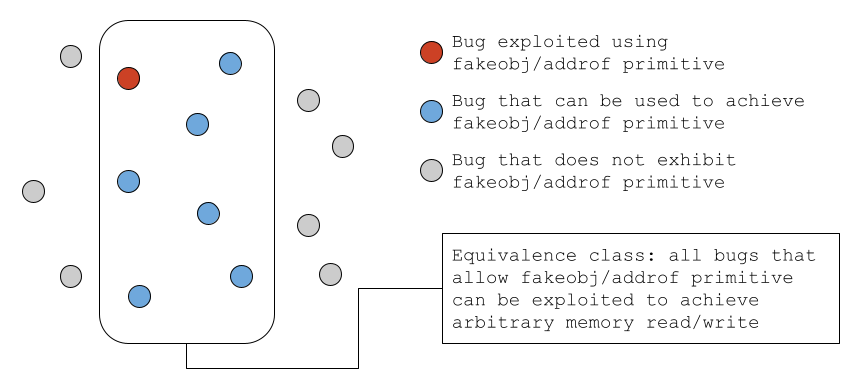
But what if the environment changes? Saelo has recently been working on a specialized sandbox for v8, Chrome's JavaScript engine. Once that has fully launched, it will no longer be sufficient to show addrof/fakeobj to prove full exploitability, because you will also need an extra step to break out of the v8 sandbox. The original equivalence class for bugs that allow the addrof/fakeobj primitive has been downgraded from "arbitrary read/write" to "sandboxed read/write", and an entirely new equivalence class for v8 sandbox escapes will be required to actually show "arbitrary read/write" (e.g. full exploitability).
One benefit to all of this is that when exploit equivalence classes become a mutual understanding, you gain a consistent communication protocol between security researchers (reporting bugs) and security engineers (receiving and triaging bug reports).
The vendor's role is to track and understand the exploit equivalence classes for their platform (tracking both public and internal exploits), to understand how changes to the platform environment will affect certain classes, and to clearly communicate their understanding back to security researchers. When a bug report falls outside of the known exploit equivalence classes, it's totally reasonable for a vendor to ask for a proof-of-concept exploit, or to work on one internally, or both.
A security researcher's role is to understand the exploit equivalence class that applies to their bug, to update their understanding as the platform's environment changes, and to provide evidence for the exploit equivalence class if necessary (such as by referring to another exploit, or by writing a new exploit).
So the answer to "is this bug exploitable or not?" is often just "yes, because the bug is in a known exploit equivalence class". It can be as simple as this: "this is exploitable because the primitive you get is just like the one in oob_timestamp.c, but you need Brandon Azad's new PAC bypass as well".
It's not always possible, however. Sometimes we can't point to an existing exploit equivalence class because there haven't been any recent exploits that are relevant. If we don't have the option to write a new exploit, then we are back in the familiar world of uncertainty and probabilities. At that point we have to use our experience and expertise to forecast exploitability, which is very challenging to do reliably. History has shown that even if one person fails to exploit a bug, it doesn't follow that everyone will -- and at the same time, history has shown that not every bug that looks like a security issue at first is actually exploitable in practice.
This shows how important exploit development should be in the defensive world. We don't write nearly enough exploits, and as a result only a portion of all bugs are actually known to be in some exploit equivalence class at the time that they're fixed. We're almost certainly labeling a lot of bugs as "high risk" that actually have highly uncertain exploitability, while also labeling a lot of bugs as "exploitation less likely" that are already known to be highly exploitable.
Another consequence is how important it is to share exploits publicly, particularly when they establish a new exploit equivalence class. In my opinion it's a momentous event each time this is accomplished, and there definitely should be credit given to anyone who successfully demonstrates a new exploit equivalence class, particularly as a platform becomes more hardened over time. In other words, the first JavaScript exploit for Chrome after the v8 sandbox is fully launched will be more "significant" than the many repetitively similar looking v8 exploits from before the sandbox was enabled. The challenge has been that it's hard to clearly differentiate why the JavaScript exploit from 2019 and the JavaScript exploit from 2024 are distinct milestones.
Exploit equivalence classes are a nice mental model, and it's a model that served me well. I suspect this is all just a description of how people are already thinking about this problem, but we're all learning about this through hard-won experience rather than a pre-existing shared language. We know that communication between security researchers and vendors is often very challenging, and disputes about exploitability are a big part of that. Perhaps then this is a reasonable starting point for improving communication and becoming a little bit more rigorous along the way.
- Ben Hawkes